
Trio:面向物理运营的世界模型
MachineFi Labs 关于 Trio 的进展更新 — 我们构建了什么、现在有什么在运行,以及如何让你的摄像头用上它。




有史以来,物理世界一直由人来运转。一个人观察正在发生的事,判断其含义,并据此行动 — 开卡车、操作产线、巡视现场。感知、预测、行动:这个闭环里始终需要一个人。
AI 先改变了数字世界 — 语言、代码、图像。如今它开始改变物理世界。一个在真实车流中开车的 AI。一个通过想象游玩方式来学习电子游戏的 AI。一个能叠好一堆衣物的机器人。它们底层共有的那个东西 — 让机器得以观察一个情境、想象接下来会发生什么、并据此行动 — 就是世界模型。Trio 是另一种世界模型。
这些都是刻意做窄的:一辆车、一个游戏、一个机器人、一项任务。但最大的物理界面早已布好线、时刻在看 — 那些架设在每个仓库、商店、工厂和照护现场上方的摄像头,记录着数以千计的小时,而如今它们除了在出事之后调取的录像之外几乎什么也产出不了。一个能在这些之上运行的世界模型 — 在完整的、实时的运营之上 — 才是真正的机会。这正是 Trio 所为之而生的。
Trio 是什么
注意这四者的共同点:每一个都只运行一件事 — 一辆车、一个游戏、一个机器人。没有一个在运行一项运营。而物理经济的绝大部分恰恰活在那里 — 午餐高峰的餐厅、把车一辆辆送进工位的洗车房、装卸卡车的仓库、忙碌经营的卖场、一条工厂产线 — 这些地方有几十个人、车辆和机器同时在动,全天候不停,全都在没人有时间看的摄像头上。
这正是 Trio 的用途。Trio 是我们面向物理运营的世界模型平台 — 不是单一的庞大模型,而是一套由三款产品组成的套件,它们协同对一项实时运营进行感知、预测与行动。语言模型学习文本如何运作,而 Trio 学习一个场所如何运作 — 里面有什么、如何流动、接下来会发生什么 — 针对你的运营,依托你已经拥有的摄像头。我们不取代语言模型;我们把物理世界交给它们。
Trio 分三个阶段运行这个闭环 — 并且按这个顺序交付。感知今天已经上线;预见与行动是接下来的工作。
如今,其中两项已经成为现实,就在你手中。 Trio-Retina(看见)把任意摄像头画面变成一份标准、实时的现场判读 — 谁在哪里、在做什么、要去哪里。Trio-Lumen(理解)让这一切可以用大白话编程 — “标记任何在非营业时段进入装卸区的人” — 全天候盯住每一帧,并将其转化为事件与告警。感知与理解,今天交付。
pip install trio-retina
Trio-Retina 是开源的 — 在你自己的机器上运行,或在 Playground 中实时试用 →
这两项是其余一切赖以构建的基础。预见与行动 — 在麻烦发生之前预判,再在现场采取行动 — 是这个闭环接下来的阶段。这个顺序是刻意的:你无法预见你尚且看不见的东西,所以我们先做了视觉。
在开放互联网上训练的模型学到的是世界看起来如何。Trio 学到的是你的运营如何运转。
在一个仓库里,它是什么样子
抛开抽象。一个装卸区,班次过半。一辆叉车正倒出工位;一名工人从两排货架之间走出来,路线恰好与之交叉。彼此都还没看到对方。

看见 — Trio-Retina 在摄像头旁的一个小盒子上运行,已经把两者都作为被跟踪的对象:叉车与人、它们的位置,以及各自的去向。
预见 — Trio 的世界模型把接下来的两秒向前推演。两条路径相交。它此前见过这一模一样的几何关系以糟糕收场。
行动 — 一道确定性的边缘安全门在大约 50 毫秒内触发交叉路口告警 — 比任何一方能反应过来都快 — 叉车被发出停车信号。一次有惊无险,而非一份事故报告。
这就是整个主张浓缩在一帧之中:不是事情发生之后你才调取的录像,而是在它发生之前那一瞬间做出的决策。
一个真正的世界模型 — 以及我们的有何不同
Trio 身处一个快速演进的领域。世界模型正是当下许多 AI 顶尖头脑所指向的方向。这个理念可追溯到 Ha 与 Schmidhuber 的 World Models(2018)— 一个智能体学习其环境的紧凑模型,并在其中“做梦”推演。Yann LeCun 认为,潜在空间中的预测性世界模型(他的 JEPA)是通往自主机器智能道路上缺失的一环;李飞飞把这一前沿称为空间智能,她的 World Labs 构建生成可探索 3D 世界的模型。这个领域大致分为几个阵营:
- 潜在空间预测 — V-JEPA 2(Meta)与 Dreamer 系列在潜在空间中学习动态并在其中规划。
- 生成式与交互式世界 — Genie 3(DeepMind)、NVIDIA Cosmos 与 World Labs 的 Marble 想象并生成环境。
- 自动驾驶 — Tesla FSD 与 Wayve 的 GAIA-2 运行着地球上部署最广的世界模型 — 为一辆车服务。
- 机器人 — Physical Intelligence、Skild AI 与 Figure 为单个机器人构建基础模型。
它们几乎都要么想象或模拟一个世界,要么对单个智能体的第一人称域建模 — 一辆车、一个机器人。Trio 则是那个在已经真实存在的、实时的第三人称运营之上运行的 — 一整座仓库或卖场、许多人和机器同时在动 — 并实时对其采取行动。
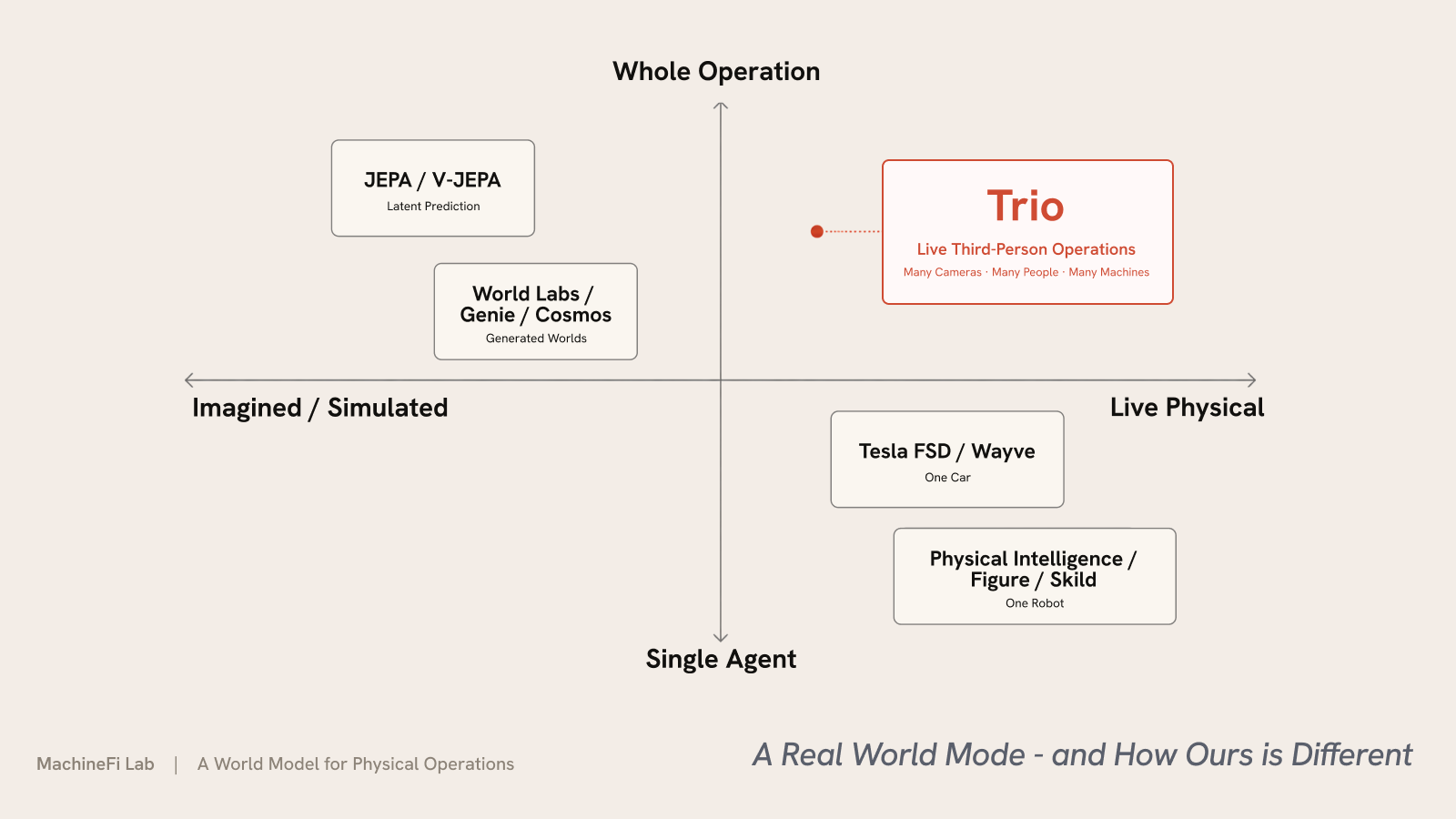
| 世界模型 | 优化目标 | Trio 的不同之处 |
|---|---|---|
| JEPA · V-JEPA (LeCun) | 在潜在空间中学习通用世界模型 — 研究 | 面向实时运营的已部署产品;专精化,而非一种架构 |
| World Labs (李飞飞) | 生成并重建可探索的 3D 世界 | 读取你的摄像头已经看到的世界;并不去生成一个 |
| Genie · Cosmos | 想象并模拟环境 | 在已经存在的空间上实时决策 |
| Tesla FSD | 驾驶一辆车 — 第一人称、单一领域 | 第三人称、多实体、一整套运营、多个领域 |
| Physical Intelligence · Figure · Skild | 一个机器人、一项任务 | 推理一整套运营接下来应当做什么 |
两个维度让 Trio 与众不同。在技术上 — 它小巧、快速、专精:在边缘端实时运行,单次查询成本下探至约 0.004 美元,按决策计费,采用一个冻结的基础模型加上小巧的每站点适配器(LoRA,以 GPU 小时计训练),而非在每一帧上重跑一个庞大的通用模型。在 OVBench 流式基准上,把一个开放权重模型封装进 Trio 的技术栈,仅凭架构就把准确率提升了 2.3 个百分点,且其感知可持续流式处理,没有前沿模型那种固定的分钟上限。在场景上 — 它运行在已经存在的运营之上,并当下就对其采取行动,而不是去想象一个世界、驾驶一辆车或挪动一个机器人。
Trio 是如何构建的
致技术团队:这里讲的是 Trio 如何保持足够的快与省,从而能在每一个摄像头上全天运行。如果你是为运营故事而来,可以略过 — 收尾的最后一句就是要点。
五条原则把整个系统维系在一起:各层之间的每个接口都是强类型、可检视的场景图(绝不是一个不透明的向量);一个路由器掌管成本,持续运行廉价的各层,仅在需要时才唤醒昂贵的推理;工具是双向的,因此推理层可以命令下层去重新审视或重新模拟;每个决策都附带其证据,因此操作员可以检视、质疑并推翻它;基础模型保持冻结,而小巧的每部署适配器 — LoRA 模块以及一个跨层融合适配器,以 GPU 小时而非完整重训计训练 — 为每个站点做专精化。
这些原则被实现为七个平面 — 单个决策路径上有六个,外加贯穿全部的治理:
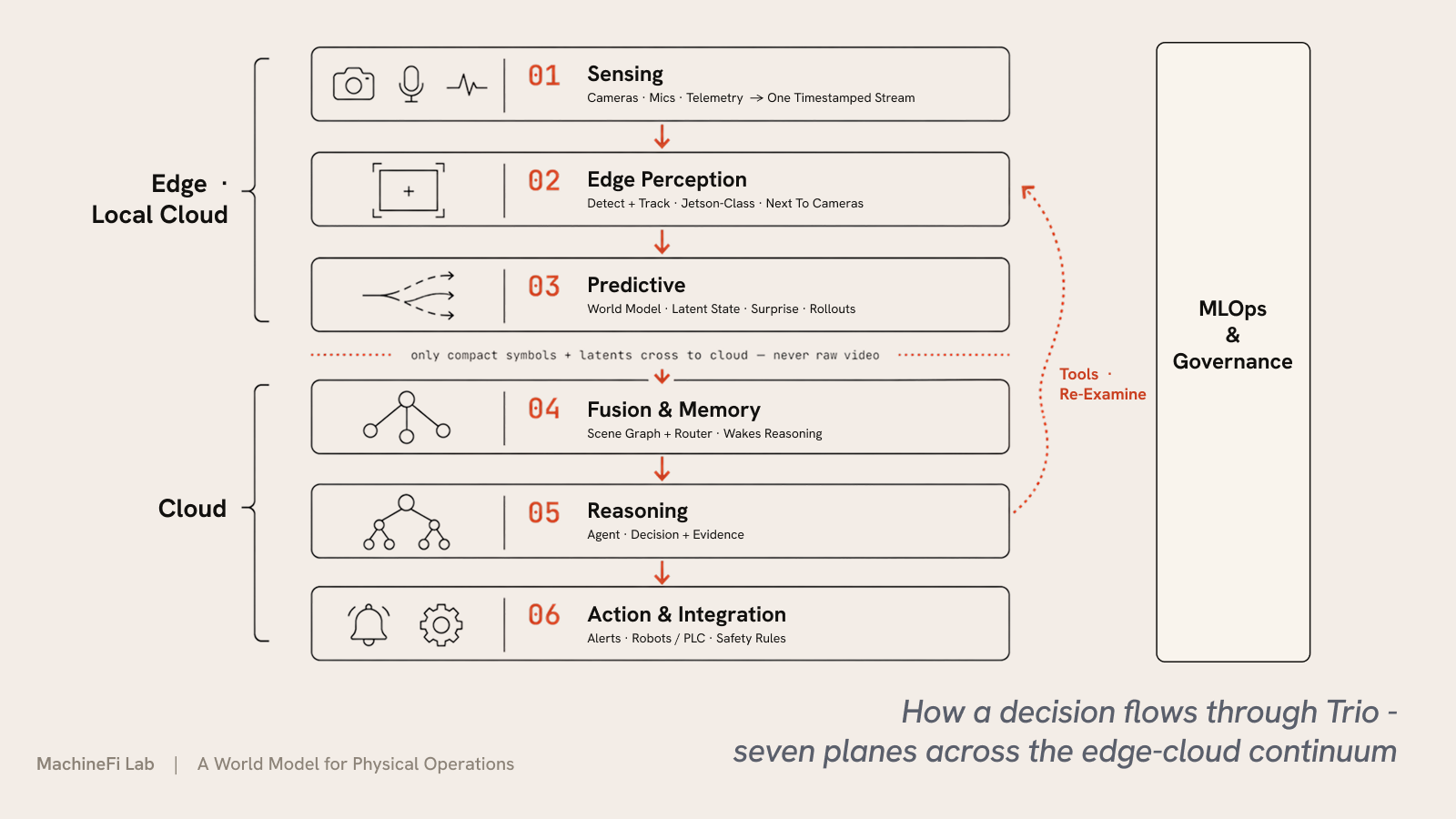
由于感知与预测在本地运行,只有紧凑的符号与潜在表征上传到云端 — 绝不上传原始视频 — Trio 按决策计费,而非按每帧每 token 计费。
Trio 运行在哪里
仓库只是一帧画面。我们开篇提到的餐厅、洗车房、卖场、工厂 — 同一个模型可以指向任何依赖摄像头运行的运营,如今与人类操作员并肩工作,呈现他们现有系统所遗漏的:








我们已经构建了什么 — 以及接下来是什么
Trio 不再是白板上的一个论点。v1.0 技术报告正式阐述了整个系统 — 感知–预测–行动技术栈、五条原则、七个平面 — 并附有两个完整推演的参考领域(一个洗车房和一个仓库),细到上文那次叉车与行人的有惊无险,由一道在约 50 毫秒内触发、远在 100 毫秒上限之内的确定性边缘安全门捕捉。Trio-Retina 是开源的(pip install trio-retina),并且 Playground 已经上线 — 打开 platform.machinefi.com/playground,在你的浏览器里看 Trio 判读真实录像。
三股力量让此刻成为时机:边缘芯片终于能在不经云端往返的情况下运行实时的运营推理;多实体场景理解已经跨过了单目标检测从未接近的研究门槛;而物理环境的运营者们已经准备好迎接当今 AI 中也许最被低估的能力 — 一个架设在他们已经拥有的摄像头之上、无需新硬件的世界模型。从这里出发,Trio 沿着这个闭环成长 — 从今天的看见与理解,迈向预见,并在适当的时候,在现场采取行动。
今天就用 Trio 起步
两种入口 — 都已实时上线:
GitHub 上的 Trio-Retina
这一开源的感知层 — 与模型无关的状态层,把任意检测器变成一份标准的事件流加潜在状态。pip install trio-retina,在你自己的机器上运行它。
平台上的 Trio-Lumen
在浏览器里看你的运营活起来 — Trio 把真实录像判读为带状态的对象、把人群判读为流动,然后把它指向你自己的摄像头,用大白话发问。
实时试用 Trio-Lumen →— MachineFi Labs 团队
关于世界模型的延伸阅读
- D. Ha, J. Schmidhuber. World Models. 2018.
- Y. LeCun. A Path Towards Autonomous Machine Intelligence. 2022.(提出 JEPA)
- F.-F. Li. From Words to Worlds: Spatial Intelligence is AI’s Next Frontier. 2025.(World Labs)
- D. Hafner, W. Yan, T. Lillicrap. Training Agents Inside of Scalable World Models (DreamerV4). 2025.
- Meta AI. V-JEPA 2. 2025.
- DeepMind. Genie 3. 2025.
- NVIDIA. Cosmos World Foundation Model Platform for Physical AI. 2025.
- Wayve. GAIA-2: a controllable multi-camera world model for driving. 2025.