
Trio: мировая модель для физических операций
Обновление от MachineFi Labs о Trio — что мы создали, что работает сейчас и как подключить ваши камеры.




На протяжении всей истории физическим миром управляли люди. Человек наблюдает за происходящим, судит, что это значит, и действует — ведёт грузовик, работает на линии, обходит цех. Воспринимать, прогнозировать, действовать: в этом цикле всегда нужен был человек.
ИИ сначала изменил цифровой мир — язык, код, изображения. Теперь он берётся за физический. ИИ, который ведёт машину в живом потоке. ИИ, который учится видеоигре, воображая, как в неё играть. Робот, который складывает кучу белья. То, что лежит в основе всех их — то, что позволяет машине наблюдать ситуацию, представить, что будет дальше, и действовать — это мировая модель. Trio — мировая модель другого рода.
Все они намеренно узкие: одна машина, одна игра, один робот, одна задача. Но самая большая физическая поверхность уже подключена и наблюдает — камеры над каждым складом, магазином, заводом и этажом ухода, записывающие тысячи часов, которые сегодня не дают почти ничего, кроме записей, чтобы поднять их после того, как что-то пошло не так. Мировая модель, работающая на этом — на целых операциях, вживую — вот возможность. Именно для этого создан Trio.
Что такое Trio
Обратите внимание на общее у этих четырёх: каждый запускает одно — одну машину, одну игру, одного робота. Ни один не управляет операцией. А именно там и живёт бо́льшая часть физической экономики — ресторан в обеденный час пик, автомойка, прогоняющая машины через боксы, склад, грузящий фуры, магазин, работающий с торговым залом, заводская линия — места, где десятки людей, машин и механизмов движутся одновременно, круглосуточно, и всё это на камерах, которые некому смотреть.
Именно для этого и нужен Trio. Trio — это наша платформа мировой модели для физических операций — не единственная монолитная модель, а набор из трёх продуктов, которые вместе воспринимают, прогнозируют и действуют в рамках живой операции. Там, где языковая модель учится тому, как устроен текст, Trio учится тому, как устроено место — что в нём, как оно движется, что будет дальше — для вашей операции, с камер, которые у вас уже есть. Мы не заменяем языковые модели; мы даём им физический мир.
Trio проходит этот цикл в три этапа — и поставляется именно в таком порядке. Восприятие доступно уже сегодня; предвидение и действие — это то, что дальше.
Сегодня два из них реальны и в ваших руках. Trio-Retina (Видеть) превращает любой видеопоток в одно стандартное, живое прочтение происходящего — кто где, что делает, куда направляется. Trio-Lumen (Понимать) делает это программируемым на обычном языке — «отмечай любого в зоне погрузки в нерабочее время» — наблюдая за каждым кадром круглосуточно и превращая его в события и оповещения. Восприятие и понимание — поставляются сегодня.
pip install trio-retina
Trio-Retina с открытым исходным кодом — запускается на вашей машине, или попробуйте вживую в Playground →
Эти два — фундамент, на котором строится остальное. Предвидение и действие — предугадать неприятность до того, как она случится, а затем действовать в цехе — это следующие этапы цикла. Порядок намеренный: нельзя предвидеть то, чего ещё не видишь, поэтому сначала мы сделали зрение.
Модель, обученная на открытом интернете, узнаёт, как мир выглядит. Trio узнаёт, как работает ваша операция.
Как это выглядит на одном складе
Отбросим абстракцию. Зона погрузки, середина смены. Погрузчик выезжает задним ходом из бокса; рабочий выходит из-за двух стеллажей по пути, который его пересекает. Пока ни один не видит другого.

Видеть — Trio-Retina, работая на небольшом устройстве рядом с камерой, уже отслеживает оба объекта: погрузчик и человека, их позиции и куда каждый направляется.
Предвидеть — мировая модель Trio прокручивает следующие две секунды вперёд. Два пути пересекаются. Она уже видела ровно такую геометрию, закончившуюся плохо.
Действовать — детерминированный пограничный шлюз безопасности срабатывает примерно за 50 миллисекунд, подавая сигнал тревоги о пересечении — быстрее, чем кто-либо из людей успел бы среагировать — и погрузчику подаётся сигнал остановиться. Едва не случившееся происшествие вместо отчёта о ЧП.
Вот весь тезис в одном кадре: не записи, которые вы поднимаете после того, как что-то случилось, а решение, принятое в то самое мгновение перед тем, как это произойдёт.
Настоящая мировая модель — и чем наша отличается
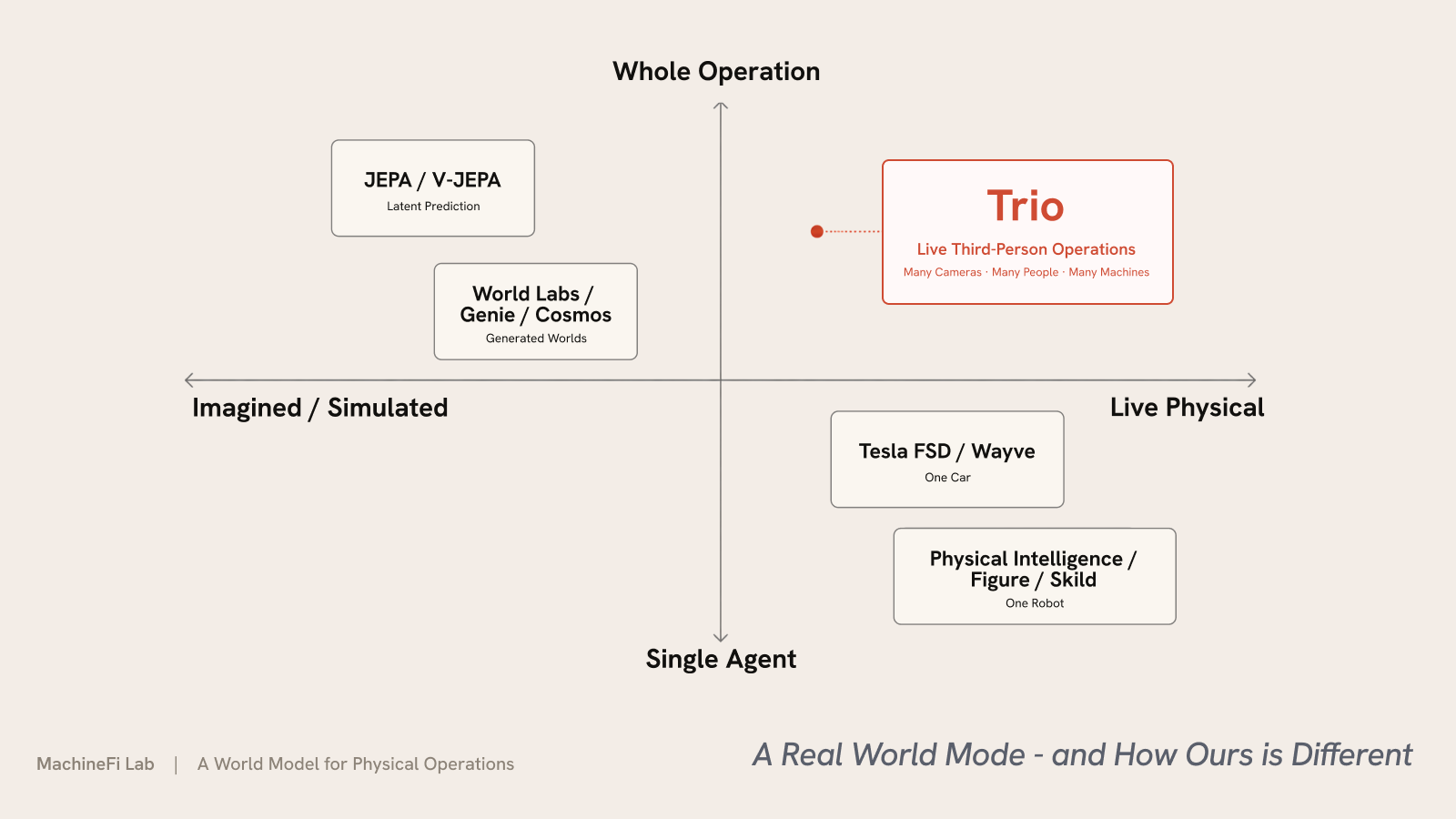
Trio находится в быстро развивающейся области. Мировые модели — это то, куда сейчас направлены многие лучшие умы ИИ. Идея восходит к работе Ha и Schmidhuber World Models (2018) — агент, обучающий компактную модель своей среды и «видящий сны» — прогоны внутри неё. Yann LeCun утверждает, что предсказательная мировая модель в латентном пространстве (его JEPA) — недостающее звено на пути к автономному машинному интеллекту; Fei-Fei Li называет этот рубеж пространственным интеллектом, а её World Labs строит модели, генерирующие исследуемые 3D-миры. Область примерно делится на лагеря:
- Латентное прогнозирование — V-JEPA 2 (Meta) и линейка Dreamer учат динамику в латентном пространстве и планируют внутри него.
- Генеративные и интерактивные миры — Genie 3 (DeepMind), NVIDIA Cosmos и Marble от World Labs воображают и генерируют среды.
- Вождение — Tesla FSD и GAIA-2 от Wayve запускают самые развёрнутые мировые модели на Земле — для одной машины.
- Робототехника — Physical Intelligence, Skild AI и Figure строят базовые модели для одного робота.
Почти все они либо воображают или симулируют мир, либо моделируют эгоцентричную область одного агента — одна машина, один робот. Trio — тот, что работает на живых, реальных, уже существующих операциях от третьего лица — целый склад или магазин, множество людей и машин одновременно — и действует на них в реальном времени.
| Мировая модель | Оптимизирует | Чем отличается Trio |
|---|---|---|
| JEPA · V-JEPA (LeCun) | обучение общих мировых моделей в латентном пространстве — исследование | развёрнутый продукт на живых операциях; специализированный, а не архитектура |
| World Labs (Fei-Fei Li) | генерация и реконструкция исследуемых 3D-миров | читает мир, который ваши камеры уже видят; не генерирует его |
| Genie · Cosmos | воображение и симуляция сред | принимает решения в реальном времени в уже существующих пространствах |
| Tesla FSD | вождение одной машины — эгоцентрично, одна область | от третьего лица, много сущностей, целая операция, много областей |
| Physical Intelligence · Figure · Skild | один робот, одна задача | рассуждает о том, что целой операции следует делать дальше |
Две оси выделяют Trio. Технически — он мал, быстр и специализирован: в реальном времени на границе, нижний порог около 0,004 $ за запрос, тарификация за решение, замороженный фундамент плюс небольшие адаптеры под площадку (LoRA, обучаемые за GPU-часы) вместо одной гигантской общей модели, перезапускаемой на каждом кадре. На потоковом бенчмарке OVBench обёртывание модели с открытыми весами в стек Trio повышает точность на +2,3 пункта исключительно за счёт архитектуры, а его восприятие работает потоково без фиксированных минутных лимитов, на которых упираются передовые модели. По сценарию — он работает на операциях, которые уже существуют, и действует на них сейчас, вместо того чтобы воображать мир, вести одну машину или двигать одного робота.
Как устроен Trio
Для технических команд: вот как Trio остаётся достаточно быстрым и дешёвым, чтобы работать на каждой камере весь день. Если вы здесь ради истории об операциях, пролистайте вперёд — итог в последней строке.
Систему скрепляют пять принципов: каждый интерфейс между слоями — это строго типизированный, инспектируемый граф сцены (никогда непрозрачный вектор); маршрутизатор владеет стоимостью, непрерывно запуская дешёвые слои и пробуждая дорогое рассуждение только при необходимости; инструменты двунаправлены, поэтому слой рассуждения может командовать нижним слоям пересмотреть или пересимулировать; каждое решение поставляется со своими доказательствами, поэтому оператор может проинспектировать, оспорить и отменить его; а базовые модели остаются замороженными, тогда как небольшие адаптеры под развёртывание — модули LoRA и адаптер межуровневого слияния, обучаемые за GPU-часы, а не полным переобучением — специализируют каждую площадку.
Эти принципы реализованы как семь плоскостей — шесть на пути одного решения, плюс управление поверх всех:
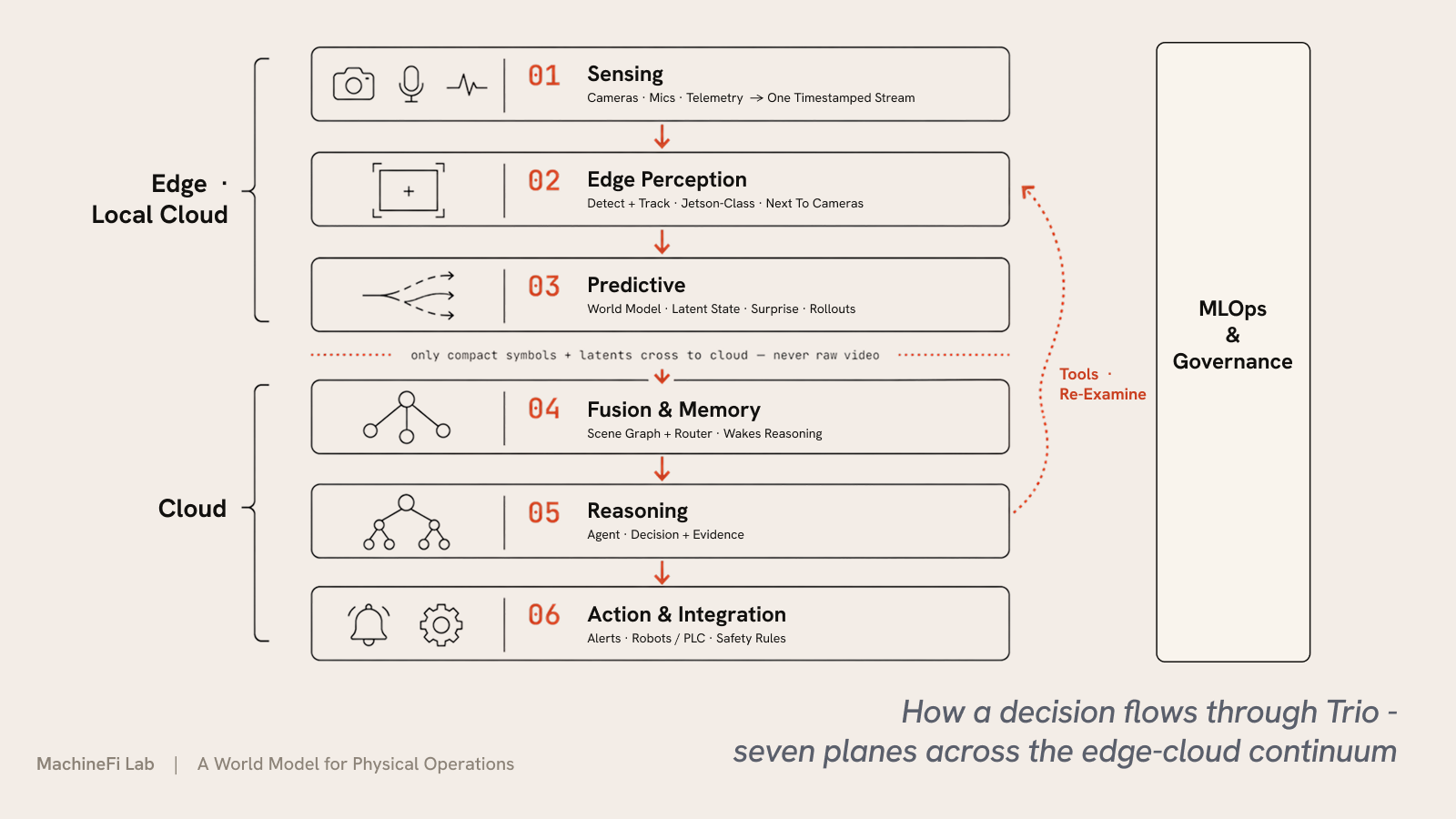
Поскольку восприятие и прогнозирование работают локально и в облако уходят только компактные символы и латенты — никогда не сырое видео — Trio тарифицируется за решение, а не за токен на кадр.
Где работает Trio
Склад был одним кадром. Ресторан, автомойка, магазин, завод, с которых мы начали — та же модель нацеливается на любую операцию, работающую на камерах, сегодня рядом с операторами-людьми, выявляя то, что упускают их существующие системы:








Что мы создали — и что дальше
Trio больше не тезис на доске. Технический отчёт v1.0 формализует всю систему — стек восприятие–прогнозирование–действие, пять принципов, семь плоскостей — с двумя полностью проработанными эталонными областями (автомойка и склад), вплоть до описанного выше едва не случившегося столкновения погрузчика с пешеходом, перехваченного детерминированным пограничным шлюзом безопасности, срабатывающим примерно за 50 миллисекунд, заметно внутри потолка в 100 мс. Trio-Retina с открытым исходным кодом (pip install trio-retina), и Playground запущен — откройте platform.machinefi.com/playground и смотрите, как Trio читает реальные записи прямо в браузере.
Три силы делают момент настоящим: граничные чипы наконец способны выполнять операционное рассуждение в реальном времени без обращения к облаку; понимание сцены со многими сущностями перешло исследовательский порог, к которому обнаружение одиночных объектов никогда не приближалось; а операторы физических сред готовы к, пожалуй, самой недооценённой возможности в сегодняшнем ИИ — мировой модели поверх камер, которые у них уже есть, без нового оборудования. Отсюда Trio растёт вверх по циклу — от зрения и понимания сегодня к предвидению и, со временем, действию в цехе.
Начните с Trio сегодня
Два пути — оба уже доступны прямо сейчас:
Trio-Retina на GitHub
Слой восприятия с открытым исходным кодом — модель-агностичный слой состояния, превращающий любой детектор в один стандартный поток событий плюс латентное состояние. pip install trio-retina и запускайте на своей машине.
Trio-Lumen на платформе
Посмотрите, как ваша операция оживает в браузере — Trio читает реальные записи как объекты с состоянием и толпы как поток, затем нацельте его на свои камеры и спрашивайте обычным языком.
Попробуйте Trio-Lumen вживую →— Команда MachineFi Labs
Дополнительное чтение о мировых моделях
- D. Ha, J. Schmidhuber. World Models. 2018.
- Y. LeCun. A Path Towards Autonomous Machine Intelligence. 2022. (вводит JEPA)
- F.-F. Li. From Words to Worlds: Spatial Intelligence is AI’s Next Frontier. 2025. (World Labs)
- D. Hafner, W. Yan, T. Lillicrap. Training Agents Inside of Scalable World Models (DreamerV4). 2025.
- Meta AI. V-JEPA 2. 2025.
- DeepMind. Genie 3. 2025.
- NVIDIA. Cosmos World Foundation Model Platform for Physical AI. 2025.
- Wayve. GAIA-2: a controllable multi-camera world model for driving. 2025.